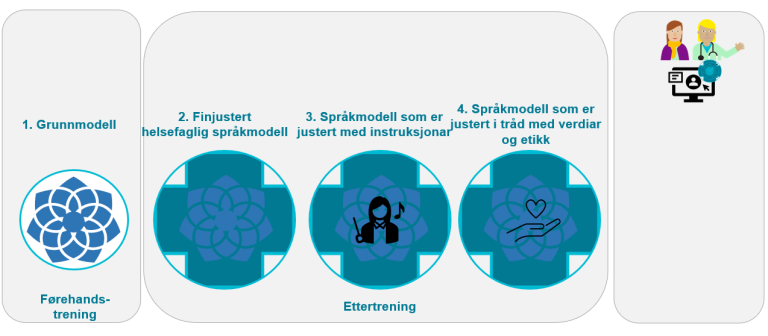
For at ein stor språkmodell kan nyttast i helse- og omsorgssektoren, kan det vere at han må tilpassast helseområdet. Ettertrening (post-training) kan t.d. gjerast ved å (fin)justere ein grunnmodell etter at den er førehandstrent, og/eller ved å rettleie ein modell mot ønska oppførsel. Vi går gjennom nokre tilnærmingar for å ettertrene og rettleie store språkmodellar på helseområdet i dei påfølgjande delkapitla.
1.3.1 Finjustering med helsefagleg innhald
Ein førehandstrena grunnmodell kan omfatte for mykje allmennspråkleg innhald. Språkmodellen kan difor med fordel tilpassast eit spesifikt fagområde, til dømes helsefag. Slik tilpassing vert kalla for finjustering (fine tuning). Det skjer ved at språkmodellen blir tilført nye helsefaglege tekstar som ny innputt og ein ny prosess med maskinlæring blir gjennomført, jf. figuren under. Heile eller delar av grunnmodellen vil då bli trena på helsefagleg terminologi, forkortingar, sjargong og så bortetter. for å kunne vere i stand til å handsame tekstar frå spesielle bruksområde, t.d. kliniske tekstar. Ein finjustert helsefagleg språkmodell vil difor vere i stand til å «forstå» fagspråket til helsepersonell betre.
I Noreg er Helse Vest IKT i ferd med å utvikle ein finjustert helsefagleg språkmodell basert på BERT-teknologien. Modellen skal etter planane vere ferdig i løpet av 2024.

Eit nytt områda i KI er finjustering av små språkmodellar (small language models (SLM)), t.d. Microsofts Phi-2, Googles Gemini Nano. Desse har langt færre parameterar enn dei store språkmodellane og er difor langt mindre ressurskrevjande. Dei kan jamvel nyttast på mobiltelefonar utan å vere kopla til internett. Små språkmodellar kan bli finjusterte med helsefaglege tekstar, men då til ganske spesifikke bruksområde pga. den relativt avgrensa modellen.[12][13]
1.3.2 Instruksjonsjustering mot helsefaglege oppgåver
Ein språkmodell som er finjustert mot helsefag er enno ikkje nødvendigvis tilpassa ulike bruksføremål, altså til å utføre spesifikke oppgåver. Slik tilpassing må gjerast med meir trening knytt til bruksføremålet.
Instruksjonsjustering (instruction fine tuning) av ein KI-modell er ein prosess der ein tilpassar ein allereie trena modell til å utføre nye, spesifikke oppgåver eller forstå nye instruksjonar betre. Dette blir gjort ved å finjustere modellen med eit mindre datasett som er direkte relevant for dei nye oppgåvene eller instruksjonane.
Dette kan gjerast ved å samle inn ei stor mengd innputtdata og utputtdata, og deretter påskjøne (belønne) modellen for å generere ønska utputt. I denne påskjøningsprosessen blir parametrane i modellen endra. Til dømes kan dette vere pasientjournalnotat som innputtdata og kodar, t.d. ICD-10-kodar, som utputtdata.
1.3.3 Justering i tråd med verdiar og etikk
Ein språkmodellen kan også bli justert i tråd med menneskelege verdiar, etiske retningslinjer, prinsipp og/eller målsettingar (alignment). Til dømes kan ein samtalerobot bli utvikla til å vere hjelpsam, ærleg og harmlaus for helseføremål. Ein modell kan til dømes lære menneskelege verdiar ved å trene på datasett som reflekterer desse verdiane. Slik justering og forbetring av åtferda til modellen kan også skje gjennom interaksjon med menneske.
1.3.4 Rettleiing med helsefagleg kunnskap
Utvikling av ein språkmodell til eit ønska bruksføremål i helse- og omsorgstenesta kan også skje i den konkrete applikasjonen. Dette steget gjev ei spesifikk rettleiing av språkmodellen slik at han utfører oppgåver på ein tilfredsstillande måte basert på helsefagleg kunnskap.
Denne tilnærminga endrar ikkje på sjølve språkmodellen, men gir heller ei slags rettleiing for korleis reisa gjennom det nevrale nettverket skal gå. Det betyr at teknikken kan brukast på både lukka modellar (som t.d. GPT-4) og opne modellar. Dette skil seg frå dei ulike stega i ettertreninga, der ein gjer faktiske endringar i KI-modellen, noko som er enklast å få til på opne modellar.
Rettleiing kan gjerast anten ved til dømes instruksjonsutforming (prompt engineering) eller kopling til ekstern, relevant kunnskap (grounding).
Instruksjonsutforming kan skje gjennom ulike formar for instruksjonar, t.d. direkte instruksar (zero-shot prompting), instruksar med eitt døme (one-shot prompting) eller fleire døme (few-shot prompting).[14] Gjennom nøye utforma spørsmål eller kommandoar kan ein språkmodell rettleiast til å generere den ønska typen respons. Dette kan skje manuelt eller gjennom bruk av ferdige sett av instruksjonsdata som effektiviserer arbeidet.
Rettleiing kan også skje ved kopling til ekstern, relevant kunnskap om til dømes medisin og helse i form av filer, lenkjer, gjennom API-ar (programmeringsgrensesnitt) og liknande innputt. I slik rettleiing kan ein leggje til rette for såkalla søkjeforsterka generering (Retrieval-Augmented Generation (RAG)) for å gje eit meir treffsikkert resultat[15]. Med andre ord skjer det ei slags kunnskapskuratering der ein vel ut nokre tekstar som er ekstra kvalitetssikra og autoritative som språkmodellen skal nytte. Desse tekstane blir indekserte og tilpassa ved hjelp av eigne verktøy. Slik sikrar ein at bruken av språkmodellen er i tråd med den etablerte kunnskapen på bruksområdet. Bruk av RAG kan på denne måten løyse problem som t.d. hallusinasjon ved bruk av språkmodellar eller risiko for utdatert kunnskap.
