Ein særskilt type treningsdata er instruksjonsdata. Slike datasett blir brukt når ein trenar maskina til å gje forventa resultat basert på ein type innputt, t.d. spørsmål og svar ("Kva er hovudstaden i Frankrike"/"Paris" eller opne spørsmål med tilhøyrande svar). Bruken av instruksjonsdata skjer i steget som er kalla instruksjonsjustering (instruction fine tuning), sjå kap 1.2 ovanfor). Instruksjonsdata er difor datasett som inneheld både innputt og utputt.[26]
Det finst opne, internasjonale instruksjonsdatasett som t.d. Databricks Dollt 15K, som inneheld 15 000 menneskelaga instruksjonar (promtps) med tilhøyrande svar.
For bruk av språkmodellar i helse- og omsorgssektoren vil det truleg vere behov for instruksjonsdata som er spesielt utvikla for sektoren. Eit døme kan vere spørsmål og svar basert på medisineksamen eller tilpassa den arbeidsoppgåva helsepersonellet skal bruke språkmodellen i. Det finst fleire internasjonale instruksjonsdatasett for helsefag, t.d. MultiMedBench[27] og MultiMedQA. MultiMedBench inneheld 14 ulike oppgåvesett frå sju ulike helsespesialitetar, inkludert genomikk. Oppgåvesetta omfattar meir enn éin million døme, sjå figur 18.
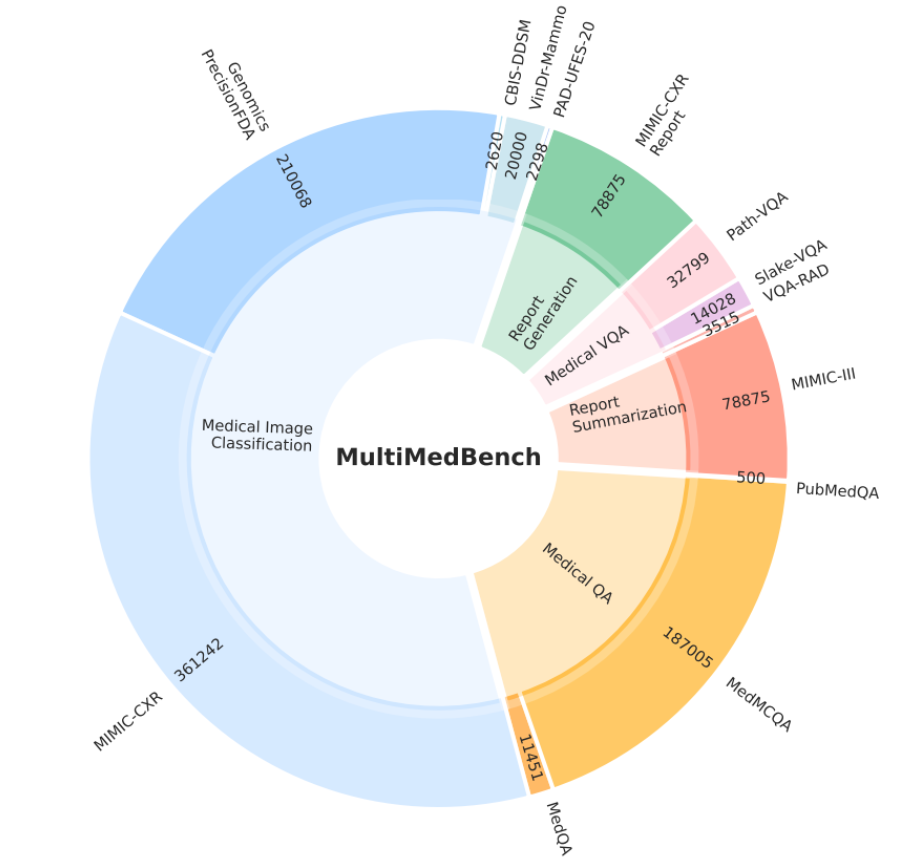
Figur 15: Samansetjing av instruksjonsdatasettet MultiMedBench [28]
MultiMedQA er eit instruksjonsdatasett som er samansett av seks ulike spørsmål- og svar-datasett med medisin, forsking og innbyggjarførespurnadar samt medisinske spørsmål henta frå nettsøk.[29]
Å utvikle instruksjonsdatasett for norsk helsefagleg bruk vil krevje spesialiserte menneskelege ressursar. Ei mogleg tilnærming vil vere å omsetje og tilpasse internasjonale instruksjonsdatasett til norske tilhøve, men det er usikkert om det er tilstrekkeleg.